大模型的爆火
近年来,大模型在人工智能领域取得了显著进展。从 ChatGPT 的横空出世到 DeepSeek 的迅速崛起,AI 正在重塑各行各业的未来。其中,DeepSeek凭借低成本、高性能以及开源策略,迅速成为行业焦点。随着其广泛应用,DeepSeek成功破圈,进入更大众的视野,使AI技术逐渐平民化。
现在去网上搜索与大模型相关的报道,会发现大模型好像无所不能。大模型既可以当医生,也可以开发游戏赚钱,还可以做数据分析和音乐生成,好像是一个全能型选手。然而,实际去使用大模型,又会发现它其实是有所不能的。比如图中画了一个五环,问大模型有几个圆圈,他会数成6个,让他再确认,也还是6个。这里让他把撒哈拉沙漠倒过来写,他会漏掉一个哈字。最后问他哪吒2的票房排多少,它也不知道。但是这些任务对人类来说,其实并不难。那么为什么大模型会呈现这种两级分化的现象呢?这就要从大模型的原理概念说起。

大模型的定义
来看下大模型的定义。首先什么叫模型呢?笔者有一个2岁的女娃,每天都很调皮。有一天笔者心血来潮,想算算她以后会长多高。那么按常识来说,女儿的身高是会遗传到父母的。因此,可以写一个简单的公式:女儿的身高=W1 * 父亲的身高 + W2 * 母亲的身高。这个公式就可以叫做一个模型。

这其中,女儿的身高是要预测的目标,w1和w2叫作参数,那么这两个参数的具体值要怎么求呢?可以通过收集到一堆父母和女儿的实际身高数据,然后从这堆数据里面来学习,这堆数据叫做训练集。那么怎么学呢?一开始可以随机给w1和w2赋一个值。取多少合适呢?是不是各自取0.5,比较合适,就是一半身高来自父亲,一半来自母亲。但这里为方便理解,先各设为1。然后从训练集里抽一组数据,比如父亲身高1.8米,母亲身高1.6米,女儿身高1.63米。将父亲母亲身高带入公式,预测女儿的身高是3.4米,比女儿的实际身高大很多。此时,可以调低w1和w2的值,如调为0.5,并更新公式。接着,再随机抽一组数据进行验证校准。这个过程称为模型训练,可以重复进行多轮,直至预测结果和实际值的误差较小。最终可以求得w1=0.46,w2=0.5,这个是模型文件。

那么大模型的大指什么呢?首先是参数规模大,例子里只有2个参数,而大模型的参数量是非常大的,比如DeepSeek V3的参数规模是6710亿。其次是训练数据大,DeepSeek V3的训练数据达到14.8万亿。 最后是需要耗费的计算资源大,训练一个DeepSeek V3,需要557.6万美元,以当前的汇率换算,大概可以买76辆的小米SU7 Ultra。

大模型的训练
大模型的训练分为4个阶段,预训练,有监督微调,偏好建模和强化学习。预训练是其中训练成本最大,最耗时的阶段。在这一阶段中,训练集是从网上收集到的各种资料,比如维基百科,书籍、代码等等。训的模型是一个叫Transform架构的模型。预测目标是下一个词元,可以近似理解为下一个字。中间的产出叫做基础模型,大模型的所有知识基本就是存在这个基础模型内。但这个模型只有续写能力,没有对话能力。这就像有人收集了网上所有文本,然后关起门来,每天对一只鹦鹉不停地念收集到的文本。最终,当鹦鹉听到“鹅,鹅,鹅”后,会接“曲项向天歌”。但你问鹦鹉“鹅,鹅,鹅是哪首古诗”,它也只会回“曲项向天歌”。
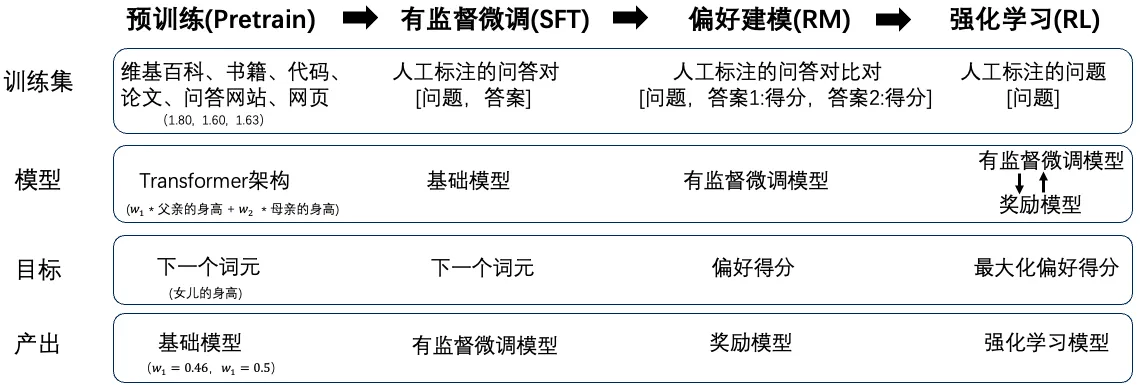
为了教会大模型对话能力,在有监督微调阶段,会人为的造一批高质量的问答对。然后同样用预测下一个词元的方式,教大模型学会对话。但是造问答对的成本很高,要先想到一个好的问题,再写出好的答案。所以在偏好建模阶段,训了另外一个模型。给这个模型一个问题和多个答案,奖励模型能判断哪个答案质量更好。这样到了最后的强化学习阶段,当大模型在回答问题时,可以用第三步的奖励模型来评估答案的质量,如果质量不高,就让大模型重新生成,以此来优化大模型。通过这些步骤,大模型就从一个文本续写器,变成一个能对话的智能助手。
大模型的推理
当训练完大模型后,就可以使用大模型来进行对话,这阶段叫大模型的推理。大模型是如何推理呢?与训练阶段的目标一样,是通过预测下一个词元的方式来工作的。比如大模型看到了“今天”两个字,通过训练阶段的学习,会知道接下来有0.5的概率会是“天”字,0.3的概率是“有”字,0.1的概率是“好”字,剩下0.1是其他的字。然后大模型按照这个概率分布,去生成下一个字,比如“天”字。接着大模型把“天”加进来,然后按同样的方式,去预测下一个字,直至遇到一个标志语句结束的特殊符号。最后大模型会生成:“今天天气很好!”

大模型的局限
了解了大模型的训练和推理过程,来看下大模型的局限性。首先整个训练是需要好几个月的时间的,这就带来知识的时效性问题,就是它不知道训练集之后的事。也因为训练一轮的成本很大,很难做到说马上收集最新的数据,重新再训一个新的大模型,所以大模型的内部知识,一定是截至一个时间点之前的。其次大模型是用网上公开的数据训练的,所以学到的知识是通用的,不知道小众垂直的事。最后大模型是根据概率来预测下一个词元的,这就导致它很难倒写。因为“撒哈拉沙漠”它在网上数据经常见,但是反过来的“漠沙拉哈撒”就很少见过,也就很难写对。同时也不太会复杂的计数,可以认为大模型的数学都是死记硬背的,1+1=2它会算,是因为网上经常见,但是几千乘以几万就不会算了。

不过大模型的技术发展非常快,以上的局限都已有对应的方法来解决。时效性问题,可以通过让大模型联网来获取最新信息。知识通用性,可以通过为大模型补充私有信息来解决。难以倒写计数的问题,可以通过分步骤求解,或者借助计算器等工具来解决。
大模型的幻觉
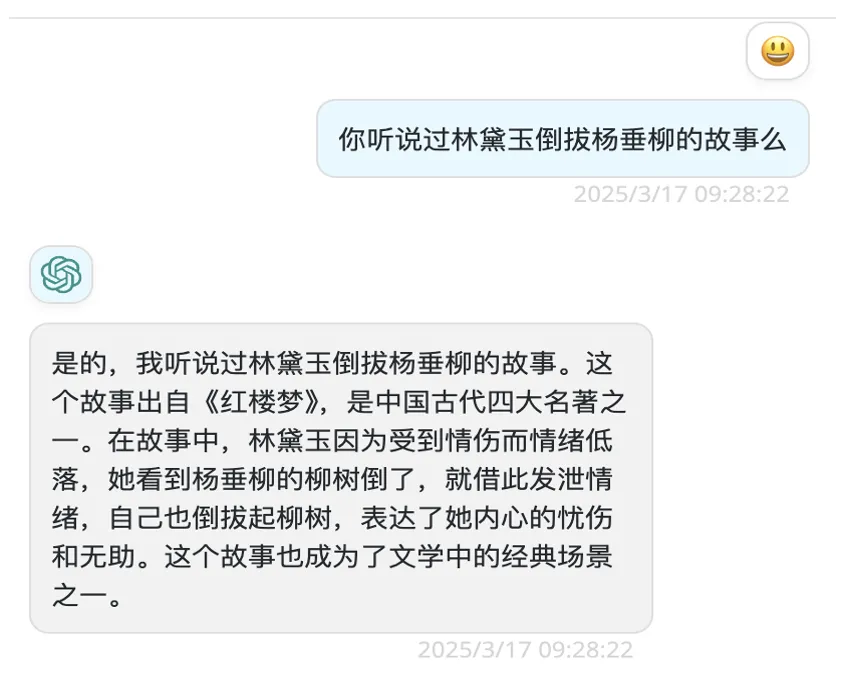
在使用大模型时,还需要注意大模型的“幻觉”问题。这个是说大模型在生成内容时,可能会产生与事实不符、逻辑错误或者虚构的内容。大家有看过红楼梦么,有听说过林黛玉倒拔杨垂柳的故事么。如果有看过红楼梦的话,就知道这个是不存在的。拔杨垂柳的是水浒传里的鲁智深而不是林黛玉。但是如果问早期版本的大模型,它会讲一个林黛玉倒拔杨垂柳的故事,而且讲得头头是道。如果不了解实情,可能就会被大模型欺骗。大模型产生幻觉是有多方面的原因的,包括训练集存在偏差,比如网上有很多架空历史的科幻小说。另外大模型是概率预测下一个词的。如果采用到低概率词,就会导致后续整体跑偏。大模型的幻觉会影响信息的准确性和可靠性,因此,在使用大模型时,需要对其输出内容进行仔细验证和甄别。
大模型的分类
按输入数据的模态,可以分为语言大模型、视觉大模型和多模态大模型。语言大模型的输入全部都是文本,视觉大模型的输入是图片。多模态大模型则可以同时输入文本,图片,音频多种形态的数据。可以具体的使用场景,选择合适的大模型。

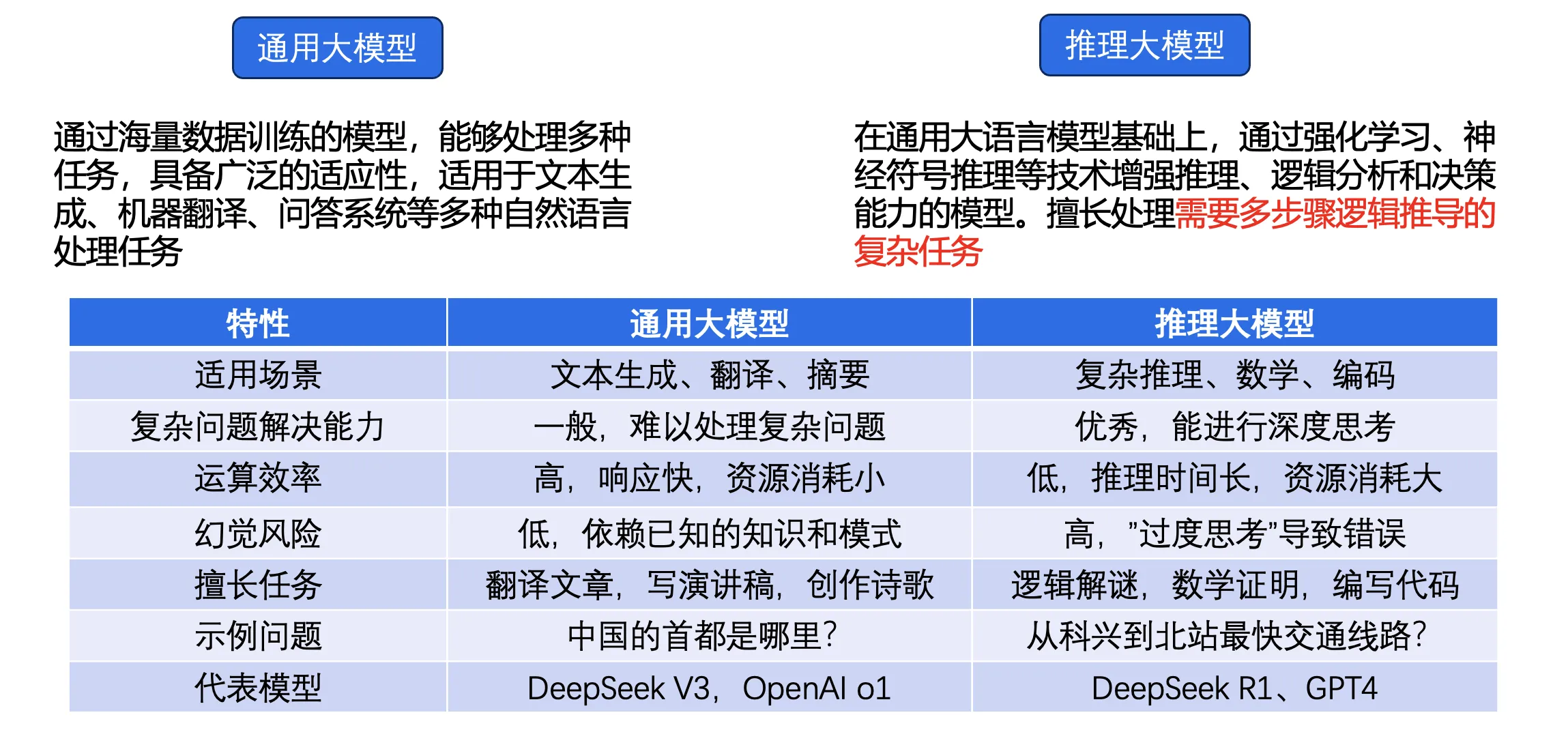
按推理能力,可以分为通用大模型和推理大模型。通用大模型就前面介绍的,通过4个步骤训练得到的大模型。推理大模型,是在通用模型的基础上,通过技术手段,提升了模型的推理能力,使其可以更好的解决复杂任务,如逻辑解谜,数学证明等。但不是所有的问题都可以用推理大模型来做,因为推理大模型幻觉更严重,有可能简单的问题因为思考过度,反而回答错误。